Data Story
Idea
The aim of this project is to extend the paper Generalization and Replication in Computational Social Science from Hai Liang and King-wa Fu. This paper managed to create a representative random sample of Twitter accounts and tested some propositions that come from other social media research paper. Our extension was to keep this network created by the research paper authors and propose two new propositions to test with the sample. These propositions come from some suppositions, some expectations about social media features, that we had in Kali data scientists group. Indeed, we thought naively that :
- There is a monthly usage pattern (certainly people post more during holidays/celebrations!)
- There is a way to predict a user's future activity based on his number of followers, followees, the number of posts, etc...
Monthly Rhythms
Let's first look at how much do people post during a year.
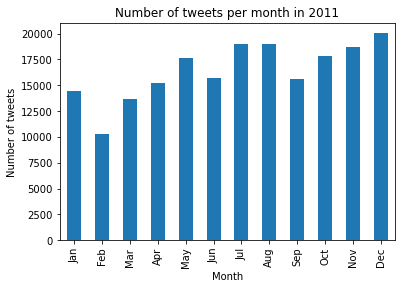
As those three graphs show us, there exists only few similarities between the years : in January, February and March, users tend to always post fewer tweets while the rest of the months do not seem to follow a defined pattern. We come up with two possible explanations: First of all, the end of year’s holidays are over and people tend to rest or go on vacation (mainly in swiss ski stations we hope), therefore leaving social media out of their lives.
The other may be that content creator, such as Youtubers and advertisers, take their vacation at this time of the year. In fact a lot of expensive ads are created before Christmas as they generate a lot of revenue and way less at the start of the year as there are no celebrations. Now, content creators’ wages are highly dependent on ads thus making those months, especially January, less profitable. Therefore, a large portion of them decides to go on vacation at this moment (once again, we hope in swiss ski stations), making less content for people to interact about on social medias.
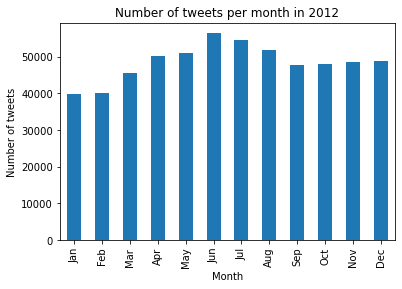
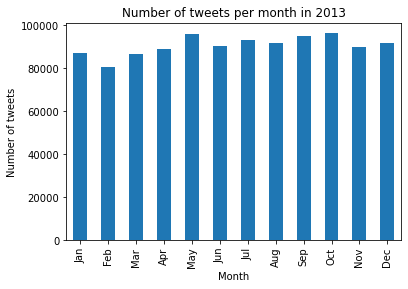
If we take a look at the other months, we can not really point out a month that is always bigger than the others or distinguish any pattern. This might be explained by different events which create a lot of discussion/post, such as the US election in late 2011 or the UEFA EURO in June 2012. Furthermore, the distribution appears to become more uniform as the user database grows. Indeed we see that overall, the number of tweets increased by 550% from 2011 to 2013.
We thus wanted to check if events had a real influence on how people tweet. We take the example of the Euro.
Looking at the number of tweets made in 2012 by Spanish speakers, who are huge football fans and followed the adventure of their team from start to finish,
a clear spike appears in June compared to the other years.
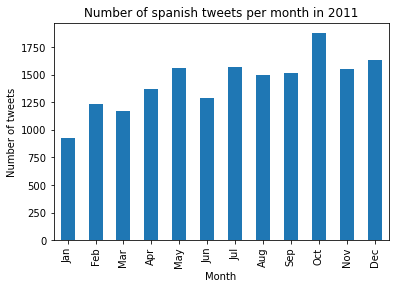
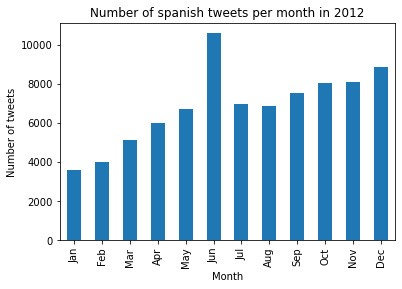
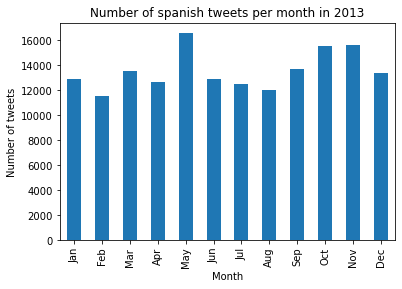
This example strengthens the hypothesis that there is no monthly pattern. It's a lot more probable that the number of tweets is correlated to what happens during the year, thus being highly influenced by predictable or unpredictable events. We could for example imagine that the number of tweets for the year 2020 would explode around March/April because of COVID and around October/November because of this historic US election, having a president that tweets a lot.
How much will a user tweet?
Can we predict how much a user will post in 2020, knowing how many followers, followees he has and how those features evolved since 2014. Of course not! But we still tried just to prove that human behaviour is highly unpredictable.
Train step
First of all, we went with a blunt try and kept the data unchanged (Spoiler Alert: didn't work well...). We tried 2 different models to predict those values.
One was Ridge Regression, the other was a Gradient Boosting Regression model.
As we are conscientious (aspiring) Data Scientists, we first performed some cross-validation on the dataset. We used the R2 value to choose our hyperparameter.
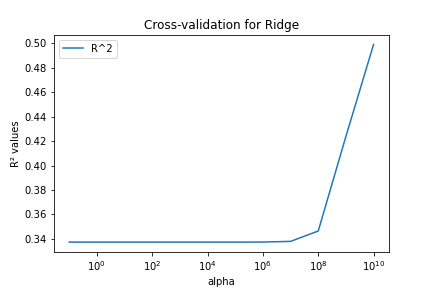
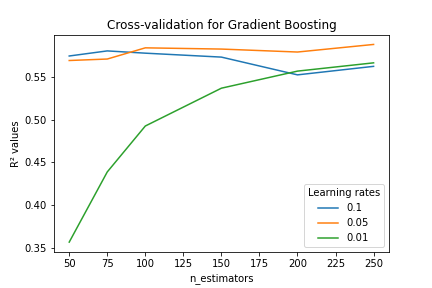
Those graphs seem to show, in addition to the best hyperparameters for both models, that Gradient Boosting manages to explain slightly better the data compared to Ridge Regression. We see that Ridge Regression performs very poorly unless the alpha parameter is in the order of 1010. Gradient Boosting on the other hand doesn't change much based on the learning rate if we consider the best model.
Test our best models
Now that we have our prepared our models and found the best hyperparameters, let's test them.
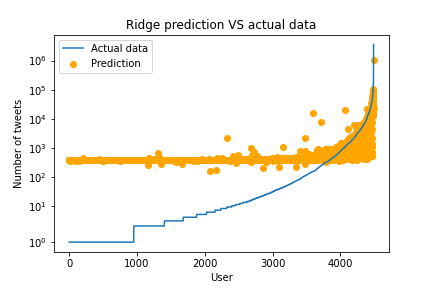
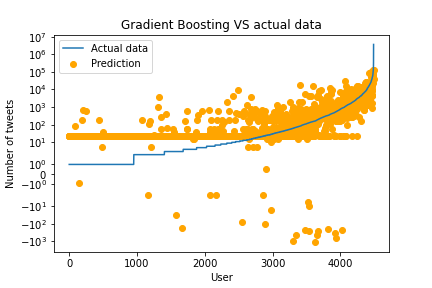
Both methods seem to give quite poor results. We can clearly see a sort of constant at the start of each graph, with the one of Gradient Boosting being lower than the one of Ridge, meaning that the models do not distinguish lower values very well. Observe that these plots were made in logscale, although Gradient Boosting seem visually to more fit the data, in reality it predicts far from the real values. We could also note that some predictions were negative, which is clearly impossible. A possible explanation is that some users can delete their tweets, or were censored by Twitter, thus making their counts lower in 2020 compared to 2014. We thus checked if we had users that have less tweets in 2020 compared to 2014:
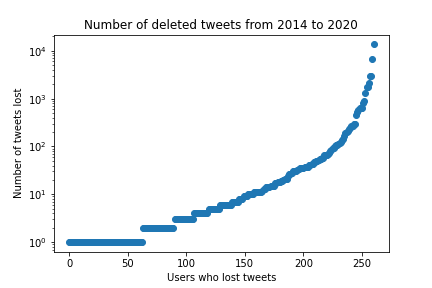
We didn't expect that much censorship. We even have that one user lost over 10'000 tweets. We can therefore ask ourselves if Donald Trump is in our dataset. Joke aside,
we need to remove these users because the model will think that they produced a negative amount of tweets, which is impossible.
Second attempt at succeeding
Armed with a well-defined dataset, we retry the above steps. We however only try this on Ridge Regression as it yield better result in the first attempt.
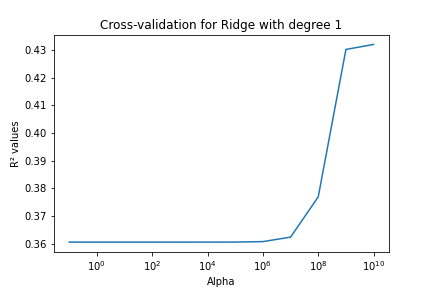
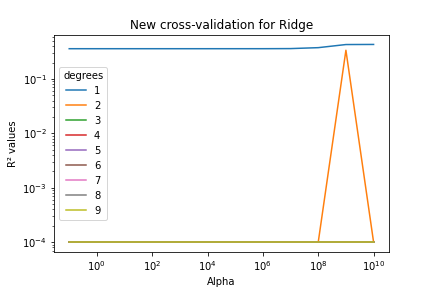
We also tried to make features extension to improve the results of our model. We see that for degree 2, we suddenly have a better R2 for 109. The other models seem to always overfit and perform thus very badly.
Test our new best models
Now, that we have new best models, we can test them once again on the test set:
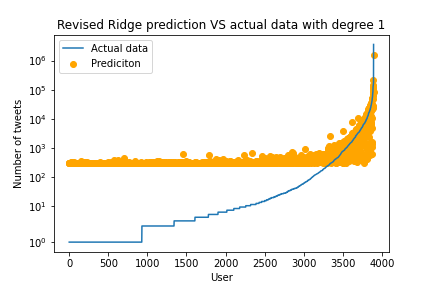
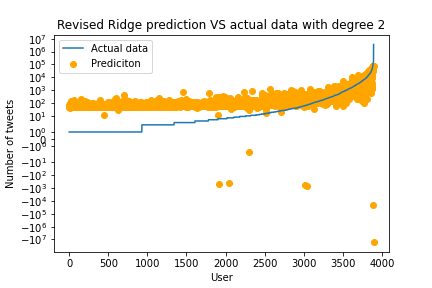
Both methods still perform really badly. Even though we got rid of the negative values, we still have negative predictions for the model on the right. We again have that there is a sort of constant line in both approaches. The standard Ridge Regression without features augmentation did not perform a lot better than previously. It seems that those models are too simplistic to predict the number of tweets someone will post in the future.
Conclusion
We first showed that there seem to be no relation between the month of the year, and the amount of tweets humans produce. Most likely, people will tweet about predictable or unpredictable events that affect them in any manner. For the second part, we can conclude that simplistic models can not perform well on such a complicated task. We also accuse the fact that data from 2014 has little to nothing to do with data from 2020 as internet tends to evolve quickly.